
In a recent article, Microsoft discussed log splitting in Data Collection Rules (DCRs), also known as Multi-Destination Data Collection Rules. Microsoft mentioned a few uses for this capability. I’ve worked with numerous clients in the past who had certain needs that log splitting would have made much simpler to fulfill. In this blog post, I’ll go over some of these requests and how this DCR feature can help to satisfy them. We will touch not only log splitting but the topic of putting the logs back together again.
If you haven’t already read the Microsoft article, I encourage you do so first. It covers the fundamentals, and I’ll rely on the methods and explanations in that post: Split Microsoft Sentinel Tables with Multi-Destination DCRs.
Log Splitting
Log splitting divides logs based on some logic and routes them to different destinations. This functionality can be used for a variety of reasons, but I’ll focus on two here: cost optimization and granular access configuration. The utility and cost of those events will be determined by how you divide the logs and where you convey them, so you must carefully design your Sentinel and Data Collection Rules.
I am assuming you have a Sentinel instance and a random Analytics table (not a Basic one) where you wish to store some (or all) of your logs in these scenarios. An Analytics table gives those logs the best level of usability. So, in my scenarios, some of the logs will go to this table, while some may go somewhere else. The ‘somewhere else’ can be one of the following:
- Send information to a secondary Basic table: Basic Sentinel tables are significantly cheaper than ‘Analytics’ tables. For cost-cutting purposes, it can be a good idea, but these tables have a lot of limitations. They have an 8-day retention restriction, the KQL you can use to query them is severely limited, and they cannot be used in rules. These are just a few of the constraints, but they are critical. Furthermore, not all tables can be upgraded to the Basic tier. Because of this, I rarely recommend using a Basic table, but it can be a viable choice in some instances.
- Send data into a secondary Analytics table with different retention or archiving settings: Data retention in Sentinel is free for the first 90 days, but beyond that, you must pay for retention or archiving. If you want to keep some data for a certain time frame and some data for a different period, you can create two tables with different retention settings and split the logs between them. This way, some logs will be rolled out earlier, thus saving some money for you.
- Another Log Analytics workspace that does not have Sentinel enabled: Please keep in mind that delivering custom logs to separate workspaces is not supported. Some native logs (such as Windows events and Syslog logs) do have multi-homing, however this is a little unstable in my experience. As a result, this option will not be covered in this blog post. But I believe this feature will be introduced in the future. But you can forward logs to multiple workspaces by using multiple Data Collection Rules, however this is independent of the log splitting functionality. I’m going to touch on this latter point though.
Please keep in mind that many of these things were achievable in the past but with a lot more effort and a more complex design. Assume you have a SaaS solution and use a Function App to read its logs and send them to Sentinel. If your connection supports DCR, you may now deploy it once and then use Log Splitting in the DCR to separate the logs.
Previously, you had to deploy the Function App, edit the code, and then send the logs to different tables based on the filters. This meant that an MSSP would have to adjust the Function App for each client based on their demands, which was not scalable. Furthermore, if the Function App was deployed from a repository, you did not have the option to alter it while keeping your code up to date.
So, check out some of the scenarios in which you can utilize log splitting.
Scenarios
Event (row)-level access control
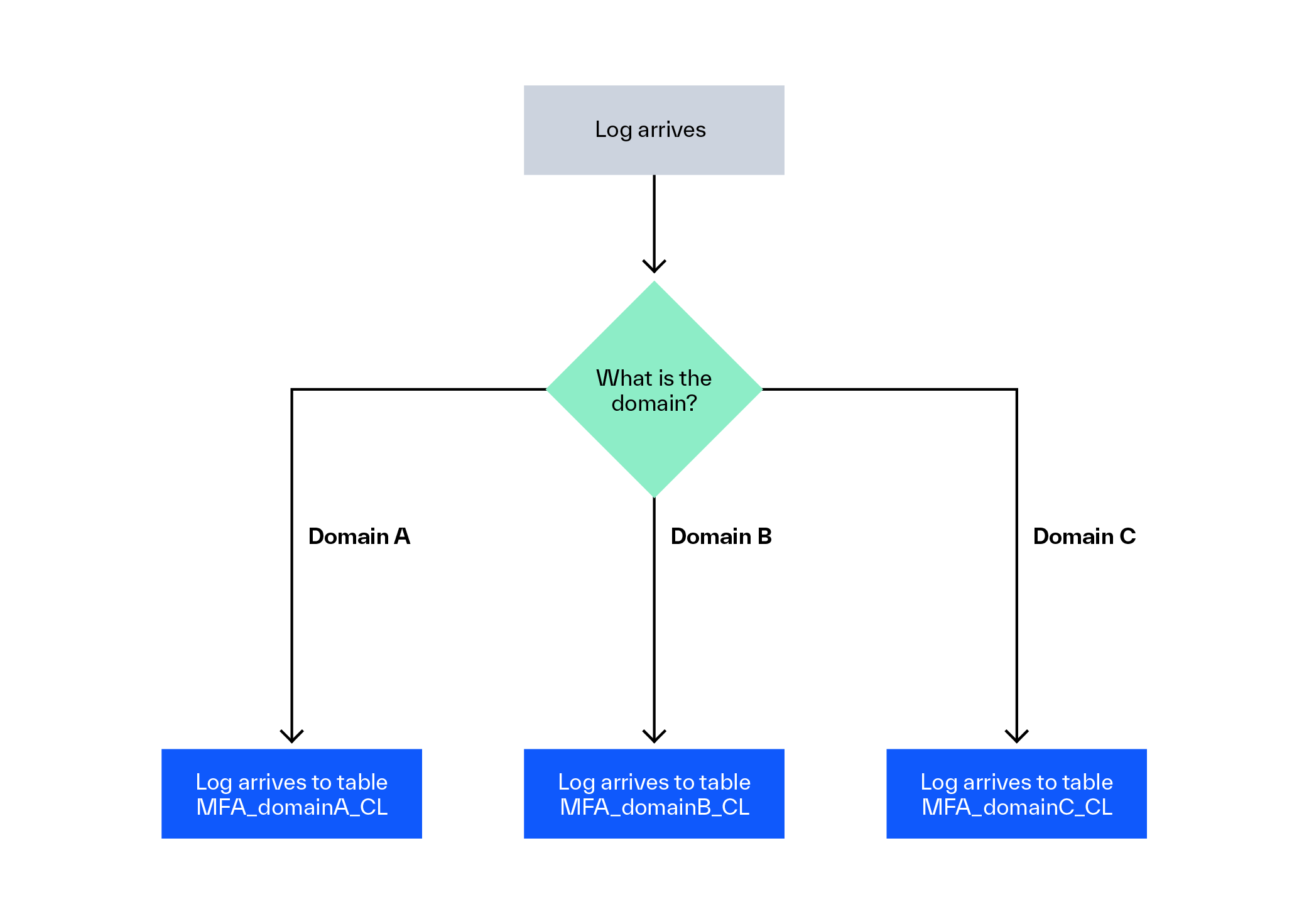
A client of mine passed MFA authentication events to a Sentinel. All of the events were read by the same Function App and sent to the same table, which we’ll refer to as MFA_CL. This table contained authentication events from many domains, in the format of user1@domain_a.com, user2@domain_b.com, and user3@domain_c.com. They desired that their SOC had access to everything, but administrators only had access to logs from their own domain.
Previously, this was not possible without altering the function app, which was not an option in my case. With log splitting, we no longer need to adjust the connector and can still fulfill this request. To accomplish this, we must take the following steps:
- Create a new table for each domain, MFA_domainA_CL, MFA_domainB_CL, MFA_domainC_CL.
- Create custom roles for each domain and assign them to people who require access to the given tables. A recent enhancement enables you to manage table-level permissions for any custom tables: https://learn.microsoft.com/en-us/azure/azure-monitor/logs/manage-access?tabs=portal#set-table-level-read-access
- Set up the DCR to split the logs into the specified tables.
The goal is to use a transformKql command to split the logs. Logs with usernames ending in ‘domain_a.com’ are routed to the MFA_domainA_CL database. ‘domain_b.com’ is stored in MFA_domainB_CL, and so on.
So, this is how the ‘dataFlow’ part of the DCR will look like after modification:
"dataFlows":
[
{
"streams": [
"Custom-MFA_domainA_CL"
],
"destinations": [
"la-1732963492"
],
"transformKql": "source | extend username = extract(';user=([^;]+);', 1, RawData) | where username endswith 'domain_a.com'",
"outputStream": "Custom-MFA_domainA_CL"
},
{
"streams": [
"Custom-MFA_domainA_CL"
],
"destinations": [
"la-1732963492"
],
"transformKql": "source | extend username = extract(';user=([^;]+);', 1, RawData) | where username endswith 'domain_b.com'",
"outputStream": "Custom-MFA_domainB_CL"
},
{
"streams": [
"Custom-MFA_domainA_CL"
],
"destinations": [
"la-1732963492"
],
"transformKql": "source | extend username = extract(';user=([^;]+);', 1, RawData) | where username endswith 'domain_c.com'",
"outputStream": "Custom-MFA_domainC_CL"
}
]
The log splitting logic in flow format:
One ‘dataFlow’ consists of these elements:
- streams: Defines the input stream – in my case it’s a custom log.
- destinations: The destination storage. In my case the id of my Log Analytics workspace.
- transformKql: The ingestion-time transformation logic that is applied to the incoming logs. This is the place where the filtering happens. We only forward logs thatare not filtered out here.
- outputStream: The name of the destination table.
Bonus
One of the really interesting things here in Sentinel is that when you query a table to which you don’t have access it won’t generate an error. It will run and return without results like the table is empty. This allows us to write a function that queries all of the tables but only shows the results to the people who have access to them.
So, for the aforementioned table, we could write the following code in a function called MFA_func:
union MFA_domainA_CL, MFA_domainB_CL, MFA_domainC_CL
When SOC, who has access to all tables, executes this function, the contents of all three tables are displayed. Admin_A, who only has access to MFA_domainA_CL, will only view the output of MFA_domainA_CL, despite performing the same function.
As a result, the developed KQL queries are highly reusable. If someone writes code in domain A that uses the function MFA_func instead of MFA_domainA_CL, someone in domain B can start using the identical code/function right away. The function will function, and they will only view the entries to which they have access. Also, if someone quits his team to join another domain, he can continue to utilize the same code he used previously; he does not need to rebuild anything.
Field-level access control
In the past, I had a client who needed specific fields to be available only by the SOC while the rest could be accessed by anyone. The concept was that while the SOC should be able to identify the individual who created the log, the operational teams should not. This info was stored in a specific field, meaning while we wanted the SOC to have access to this field we did not want other teams to see this info.
Assume we have the MFA_CL table with the following columns:
- InternalTime
- UserEmail
- MFAStatus
- LoginStatus
This is the format of a log:
internaltime=2023-08-08 12:00:00;useremail=test@domain_a.com;mfastatus=enabled;loginstatus=success
So, we need a table with all of the fields except the UserEmail one, to which we can grant access to the operational team. We also require a table with all of the data for the SOC. However, putting all of the fields in one table (n fields) and all but one (n-1 fields) in another would double the cost. A better solution is to maintain all of the fields except the UserEmail information in one table (n-1 fields) and then keep the UserEmail alone (1 field) in a distinct table. But in this case, we need the ability to find the related entries in the two tables, so the SOC can have the full picture.
There is an excellent approach to accomplish this. The hash of the fields can be calculated using an ingestion-time transformation in a DCR. During my test, I collected all of the data and stored it in the RawData column, so my hash function was rather simple. I calculate the sha256 hash value of the RawData field.
After the sha256 value is calculated I remove some of the fields from the logs, then I attach the hashvalue field to the log.
"transformKql": "source | extend hashvalue = hash_sha256(RawData) //calculate hash | parse with RawData before 'useremail=' useremail ';' after //find out what we need and don't need | extend RawData = strcat(before, ';', after, ';hashvalue=', hashvalue)" //recreate a log with the fields we need + the hashvalue field
Then a similar one can be used for the MFA_SOC_CL that will only contain the hash and the username:
"transformKql": "source
| extend hashvalue = hash_sha256(RawData)
| parse with RawData before 'useremail=' useremail ';' after
| extend RawData = strcat('useremail=', useremail, ';hashvalue=',hashvalue)"
The only supported hash function in an ingestion-time transformation is hash_sha256().
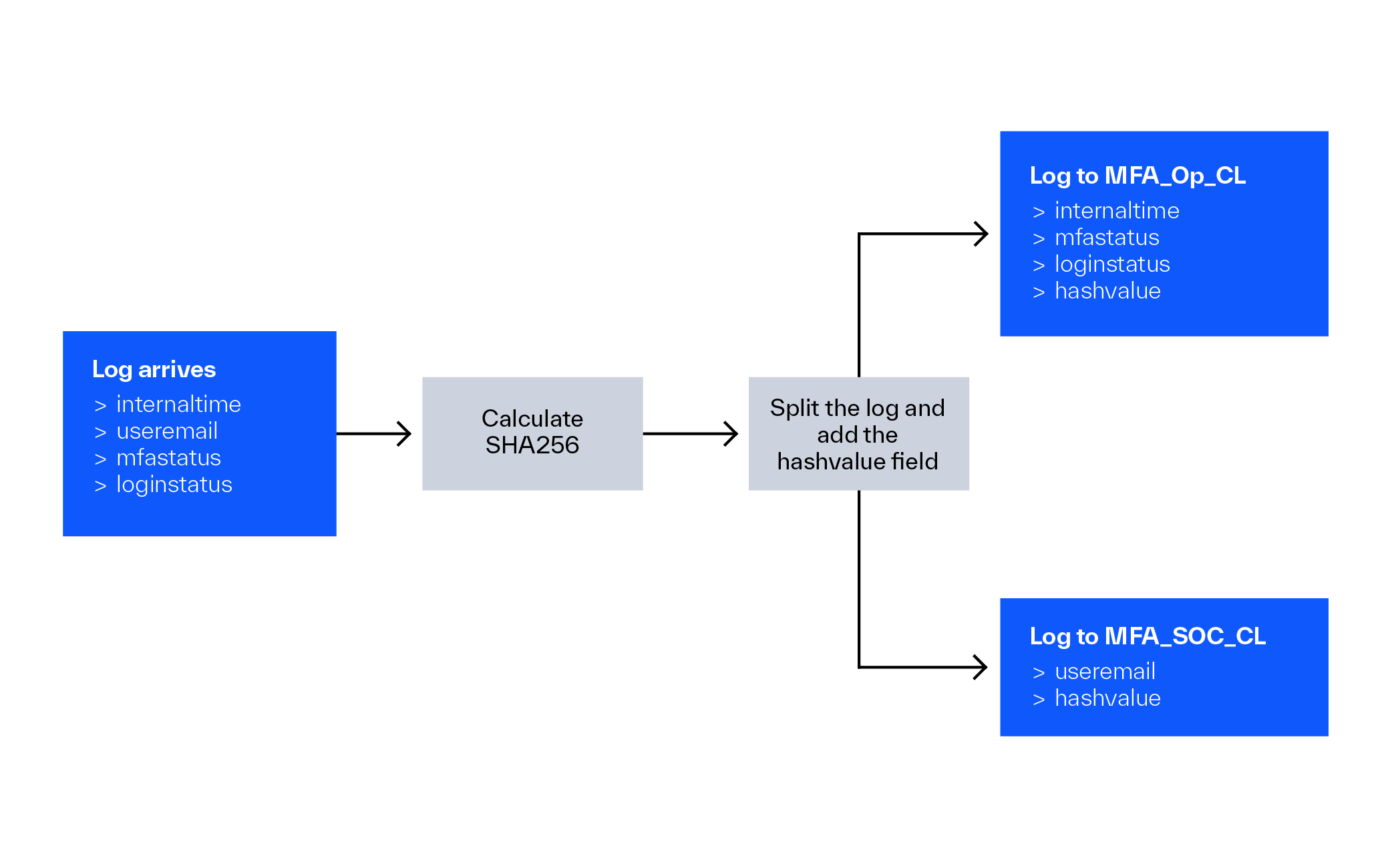
In the end, you will have an MFA_Op_CL table without the UserEmail but with the hash value, and an MFA_SOC_CL table with only the UserEmail and the hash value. Just like in the previous example, one may write a function that combines the two tables based on the hash value. As a result, the MFA_func function could look like this:
MFA_OP_CL | join MFA_SOC_CL on hashvalue
When a member of the operational team runs this query, he does not have access to the UserEmail, however the SOC running the identical function has access to all data, including the UserEmail. So, while the operational team won’t see the ‘hidden’ info the SOC will have all the informations by running the same function.
Bonus
As previously stated, sending logs into different workspaces with a single DCR is currently NOT OFFICIALLY SUPPORTED and will result in an error. However, it is still possible to process the same logs with two DCRs and then correlate them based on the calculated hash value. This is ineffective from a network standpoint, but it can still be a cost-effective solution.
A good example for this is when you want to deal with firewall logs. Firewall logs are notoriously pricey. Some firewalls can have 40-50 distinct fields with a lot of information in them, which can be not only pricey but also worthless from a security standpoint.
It’s possible that your rules only use a few fields in a firewall log. You have a few Analytics rules in place, but they all require only a small fraction of the fields available from your firewall. Perhaps your SOC or operational teams require a few additional fields, but even they will not use every one of them. There may also be some compliance requirements in places that need all fields to be saved somewhere.
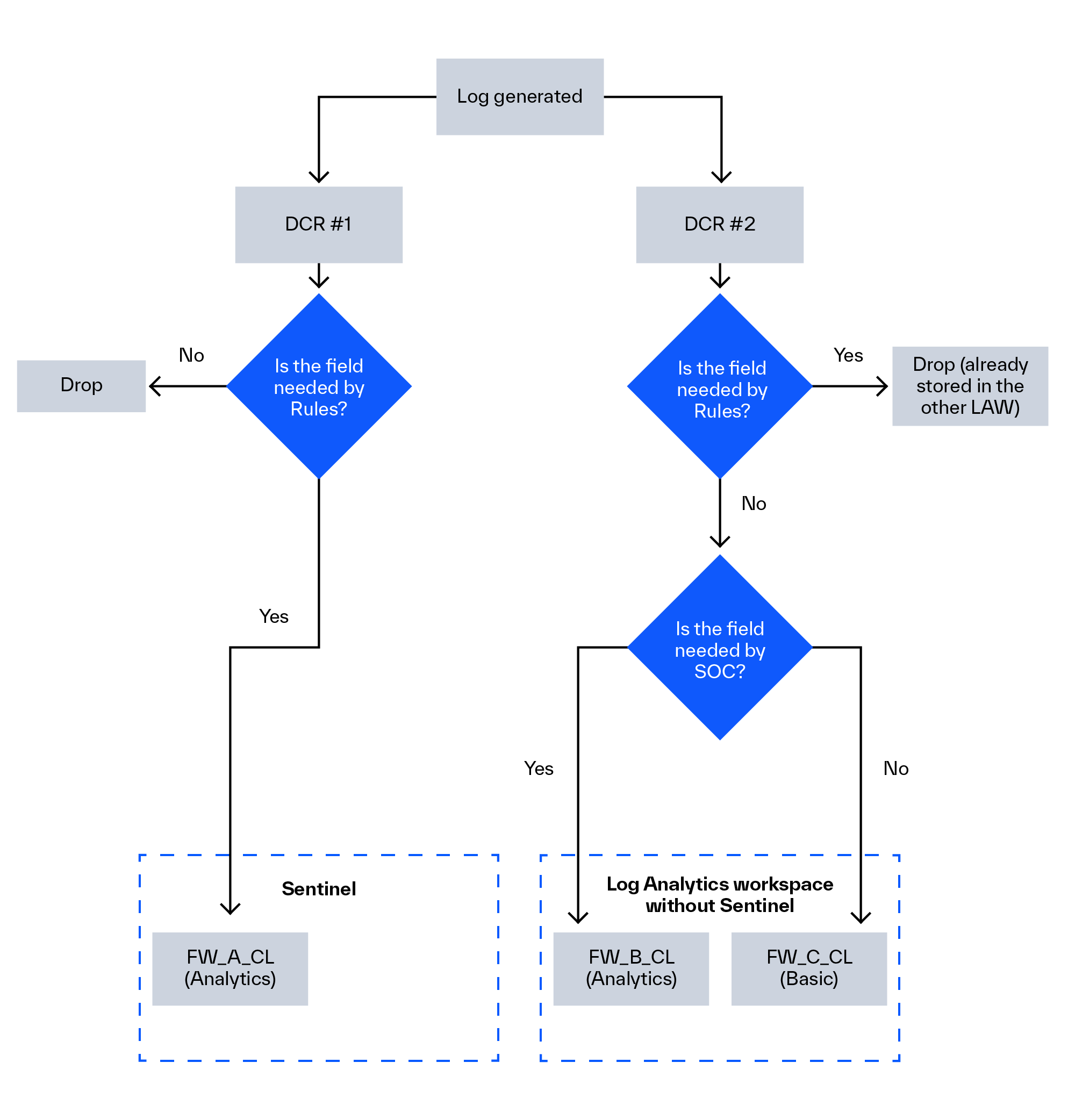
You can create different tables with different information based on the varying requirements:
- FW_A_CL: A Sentinel instance with the FW_A_CL table, which has all of the fields required by the rules. Sentinel must be activated on a Log Analytics workspace before a rule may query this table.
- FW_B_CL: All data not in FW_A_CL that is required by the SOC or other teams (DFIR or Threat hunt teams). This table can exist in a Log Analytics workspace without a Sentinel on it. Data in a Log Analytics workspace that does not include Sentinel cannot be queried by a rule, but it may be queried by various automations or analysts from the other Sentinel instance.
- FW_C_CL: All other data (or all data) in a workspace without Sentinel in a separate Basic table table. You want to keep everything for compliance purposes, but you do not require this data by your rules or analysts. For this purpose you can use a cheap Basic table and then archive the data after the 8-days fixed retention period.
It is crucial to note that you cannot currently transmit custom logs into several Log Analytics workspaces using a single DCR. However, you may address this issue using two DCRs. The first DCR will send the logs with the appropriate fields to the Sentinel into an Analytics table, while the second DCR will send the rest of the logs into a secondary Log Analytics workspace that does not have Sentinel enabled. So, you can send the various fields into different destinations this way:
Also, keep in mind that the Basic log type has restricted capability. They only support a limited set of operators. As an example, because the join command is not available, you will be unable to correlate this data set to the other two tables based on the ‘hashvalue’ field. However, there are several solutions:
- Instead of keeping only the remaining fields, you can save the entire log in a Basic table, eliminating the need for correlation. Because Basic logs are so inexpensive, this can be a good solution in many circumstances.
- Basic logs are kept for 8 days. Following that, you either discard the logs or submit them to Archive. Any logs that are recovered (with a search job or restore functionality) will be stored in a new Analytics table. Because the recovered logs are in an Analytics table, you can apply any operator on them, and you can correlate them to any other Analytics tables.
Cost Calculation of the Bonus Scenario
And here is a quick calculation to show how much money you can save with this final configuration. Assume you have a firewall that generates 10 GB of data every day. You wish to transmit the data to two Log Analytics workspaces, one with Sentinel and one without. The data stores are located in North Europe.
In North Europe, the cost of 1 GB of data for Sentinel (containing both the Sentinel and Log Analytics workspace cost elements) is: 4.77 EUR.
In North Europe, 1 GB of data costs 2.549 EUR for LAW only.
In North Europe, 1 GB Basic logs cost 0.555 EUR for LAW alone.
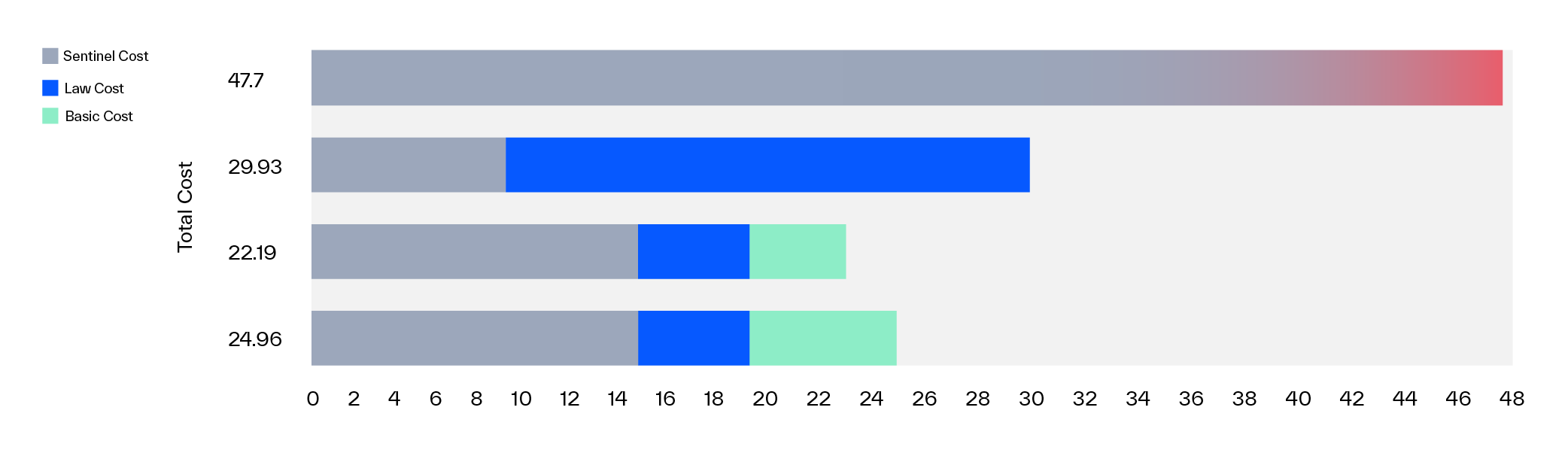
- If you wish to save all of your data in Sentinel, it will cost you 4.77 x 10 = 47.7 EUR every day.
- If you just want to maintain 20% of the data in Sentinel and the rest in a LAW-only table, the cost is 4.77 x 2 + 2.549 x 8 = 29.932 EUR
- Or a more realistic scenario would be having 30% of the fields in Sentinel, 20% of the fields in an Analytics table in a LAW-only workspace and the remaining 50% in a Basic table: 22.183 EUR
- The same arrangement if all of the data is kept in the Basic table, so no correlation will be needed: 24.958 EUR
See the cost of the 4 options on this Sentinel chart as well (in the picture the Sentinel cost includes the cost of both the Sentinel and the Log Analytics workspace element for the given workspace):
Obviously, it depends on your log source, but in the case of some noisy sources, you can drastically reduce the cost while maintaining the usability of your logs from both a security and an operational standpoint by using proper log splitting.
Important Takeaways
I’ve compiled a list of the most important points from this blog post:
- Using DCRs, you may reduce costs while also configuring more granular access control for your tables.
- By hashing the log content, you can later restore the logs even if different fields are stored in various tables. During an ingestion-time transformation, the sha256 function is the only supported hash function.
- If you use a function that unions many tables, you will only see the output of the tables to which you have access. Tables that you do not have access to will seem like empty tables to you.
- Basic logs will end up in an ‘Analytics’ table after pulling them back from Archive (_RST or _SRCH logs). This increases the usability of these logs.